The Illusion of Thinking: What Apple’s Latest AI Research Really Says

Same Trick, Different Costume: How AI Companies Rebrand “Reasoning”
Before we look at what Apple tested, it helps to see the bigger picture. Almost every major AI company now claims its models can reason. Not just answer, but think. The catch? Everyone uses a different name for what is, in practice, the same basic idea:
The model writes more steps before it gives you the answer.
Prefer watching? Here you go!
Some call it thinking. Others call it reasoning. A few call it Big Brain. But under the hood, it usually means the model is trained or prompted to produce longer, step-by-step explanations and to try more paths before committing to a result.
In mid-2025, Apple's Machine Learning Research team published a provocative paper titled The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity. The title alone challenged a prevailing narrative in AI: that modern large models can truly reason like humans.
What Apple Researched
Apple's team studied Large Reasoning Models (LRMs) - AI systems designed to solve multi-step problems by simulating a chain of thought before giving an answer. Think of these as advanced language models that pretend to reason.
Instead of relying on usual benchmarks like math or coding tests (which models may have seen during training), Apple researchers built custom puzzle environments with controlled difficulty.
These included:
- Tower of Hanoi
- River Crossing
- Checker Jumping
- Blocks World
Each puzzle can be scaled in complexity so the researchers could measure how performance changes as problems get harder. (DEV Community)
Before looking at the results, it helps to know that the tests were designed to stress how models handle different levels of problem difficulty. The same models were run on tasks that ranged from very simple to very hard, to see when step-by-step reasoning helps and when it fails.
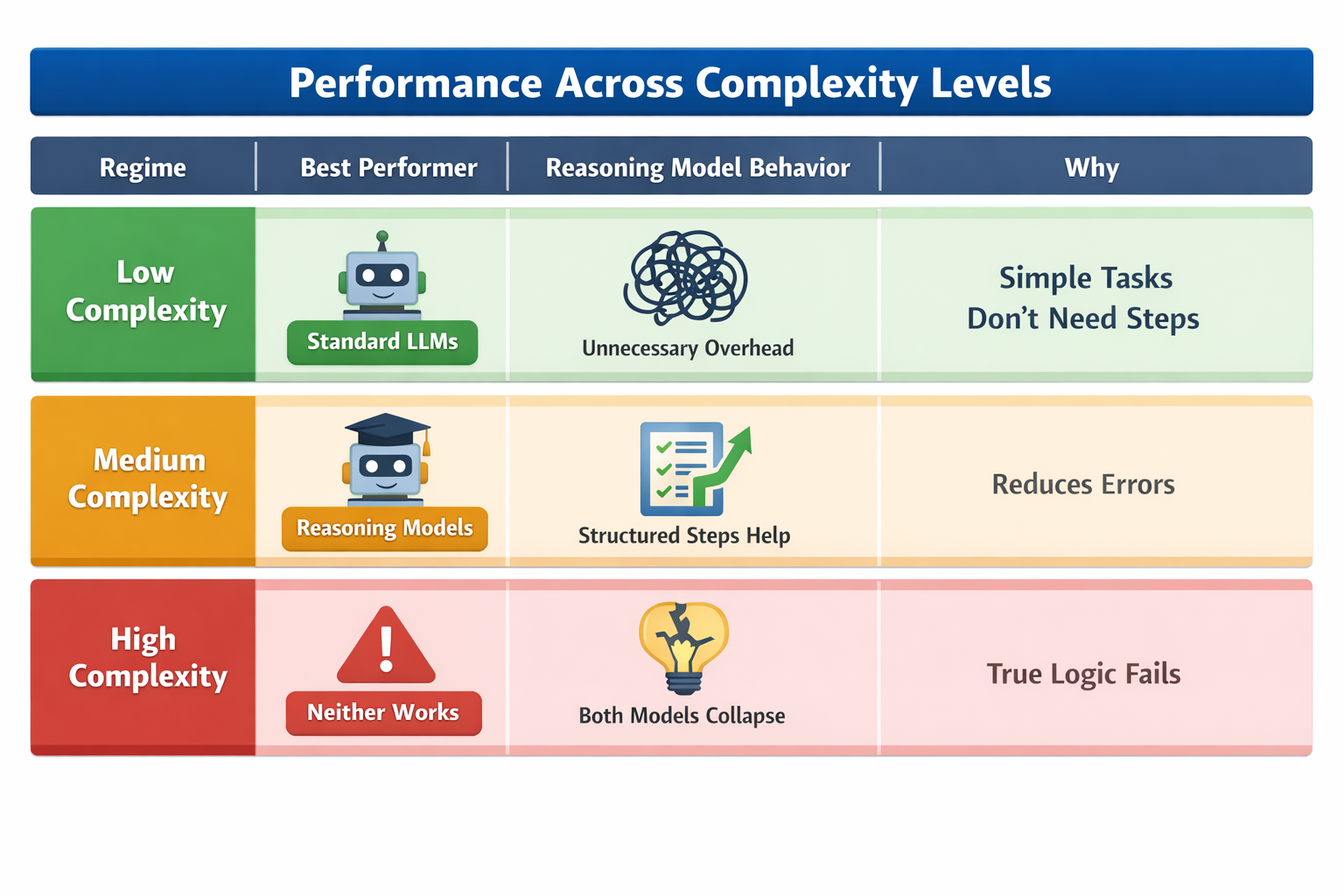
Low-Complexity Problems - Simpler Tasks Where “Thinking” Hurts
What's going on?
On easy tasks, standard language models (those that just produce direct answers) often perform better than reasoning models that generate step-by-step explanations.
Why this happens?
Overthinking: Reasoning models can overthink trivial problems. They might quickly know the right answer but then continue generating reasoning steps that lead them astray.
Extra overhead: The chain-of-thought mechanism adds overhead - more tokens, more computation - without adding value on tasks that are straightforward.
Standard LLM strengths: A basic model that has learned common patterns can often answer simple questions efficiently and accurately without reasoning.
Key insight
More thinking isn't always better - for easy tasks, it can actually reduce performance.
Medium-Complexity Problems - Where Reasoning Helps
What's going on?
Once tasks require intermediate levels of logical steps (e.g., planning three or four steps ahead), reasoning models start to pull ahead.
Why this happens?
Structured problem solving: Breaking a task into sub-steps helps trace paths toward correct answers when there are multiple steps to consider.
Self-correction and guidance: Chain-of-thought allows the model to check itself internally and reduce mistakes that simple end-to-end models make.
Example situations: Tasks where premature assumptions lead to wrong answers. Problems where intermediate checks reduce cascading errors.
Key insight
Reasoning traces do pay off when problems are complex enough to benefit from staging, but not so complex that they overwhelm the model.
High-Complexity Problems - Collapse of Performance
What's going on?
At high levels of complexity, both standard and reasoning models break down. Their accuracy drops sharply - and in some cases to near zero - even when the model still has unused token capacity.
Complete accuracy collapse: Models fail to find correct solutions consistently beyond a complexity threshold.
Reduced reasoning effort: Counterintuitively, reasoning models often spend fewer tokens thinking on harder tasks, as if they “give up” before using their full token budget. ([Vofer][6])
Inconsistent logical execution: Even given explicit algorithms, models struggle to follow exact computational steps reliably.
Possible reasons
Limits in representation: The models may lack true abstract reasoning capabilities and instead rely on statistical patterns that fail when complexity exceeds training distribution patterns.
Token planning limits: Models might implicitly optimize for shorter traces rather than reliable problem solving, leading to early termination of reasoning.
Key insight
There appears to be a threshold beyond which current reasoning mechanisms don't scale - additional token budget or longer reasoning chains don't rescue accuracy.
Why These Regimes Matter
Across these complexity regimes, a pattern emerges:
Low complexity: Reasoning adds noise.
Medium complexity: Reasoning helps.
High complexity: Both model types fail - even when they should have enough capacity.
Researchers describe this result as the illusion of thinking. The models appear to reason when breaking tasks into steps helps in the middle range, but when true compositional logic is required, this “thinking” collapses. The detailed chain-of-thought output looks like reasoning, but under stress, it does not reflect deep, generalizable logic.
Where is this leading us?
AI researchers and engineers have long debated what “reasoning” in AI actually means. Apple's work doesn't say that reasoning-enabled models are useless - but it does caution that:
Simulated reasoning isn't the same as genuine logical problem-solving.
The systems often fail to use explicit algorithms or consistent logical strategies.
High performance on benchmarks can be misleading.
Models may exploit patterns seen in training data rather than truly thinking through novel problems.
These findings remind us of a long-standing concept in AI: the ELIZA effect - where people assume a machine understands because its output sounds intelligent. In reality, the system may just be generating plausible responses based on patterns it has learned.
Community Reaction
The paper drew strong reactions.
Some welcomed it as a needed reality check on how we talk about AI “reasoning”. Others pointed out that the test setup may not reflect real-world use cases and that failures could be due to limits like token budgets, not fundamental lack of reasoning.
For example, members of the AI community published a response paper titled The Illusion of the Illusion of Thinking, arguing that Apple's conclusion about reasoning limits might be an overinterpretation.
In Simple Terms
Imagine watching someone solve a puzzle. If they use known rules and apply logic consistently, we'd call that reasoning. But if someone mimics what reasoning looks like - by parroting steps that seem logical without really understanding - the result might look smart on the surface but lack real cognitive depth.
That's what Apple's paper suggests is happening with current reasoning models: they can simulate thought processes, but they don't reliably think.
What's Next for AI Research
This work highlights important directions:
- Better evaluation frameworks.
- We need tests that actually probe true reasoning, not just pattern-matching.
- Architectures beyond current language models.
If the goal is true general intelligence, future systems might need new designs that combine pattern recognition with logic, planning, and grounded understanding.
Bottom line
Apple's “illusion of thinking” isn't a dismissal of all AI progress. It's a clear reminder that sounding intelligent is not the same as actually reasoning. As AI adoption spreads across industries, understanding this distinction will matter for developers, leaders, and users alike.
